今天要來看如何用requests抓取html
跟之前一樣要使用requests要先安裝
pip install requests
今天我們想抓這個網頁的html

這裡的<response [200]> 其中的200代表的是有成功從網頁中獲得資料
連線成功的意思
而現在我們只有讀取到而已,還沒有把資料保存下來所以我們要保存
用一個變數去儲存他,這裡我們用res
requests.get('https://www.ptt.cc/bbs/movie/index.html')
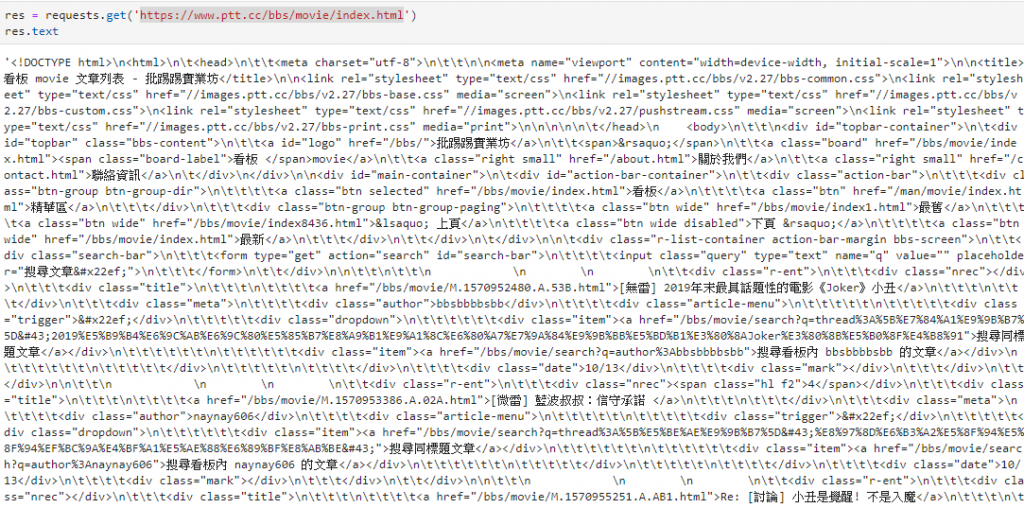
而我們需要他的txt檔去查看html存下來的紀錄
res.text
而如何知道抓下來的跟網頁的是否一樣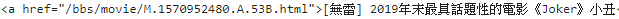
我們記住剛剛抓下來的這行
取查看剛剛ptt的網頁原始碼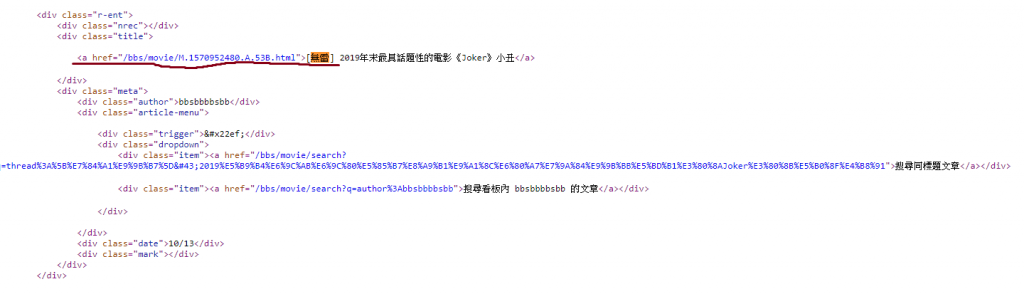
就能發現成功抓到囉!


 iThome鐵人賽
iThome鐵人賽